Guide complet : Industrialiser un projet d’IA conversationnelle.
Guide : Deployer un projet IA conversationnel à l’échelle.
La plupart des projets d’IA conversationnelle ne seront jamais mis en production.
La raison ?
Des hallucinations, des données inventées, des périmètres fonctionnels trop larges.
Il est très facile de réaliser un POC de projet d’IA conversationnelle.
Il est très difficile d’industrialiser un projet de ce type.
Nous parlons en conséquence de cause, avec Leveragers, nous avons récemment développé un Assistant conversationnel pour Visa. Tous les challenges étaient réunis :
- Tolérance 0 pour les risques réputationnels
- Nécessité de respect du RGPD et autres réglementations
- Nécessité d’identifier les tentatives d’attaques du systèmes
- Identification des biais, nécessité d’avoir des réponses parfaites
- Maîtrise des coûts à l’échelle, avec de grands volumes
- Maîtriser la vitesse de réponse à l’échelle et en respectant des standards de sécurité élevé.
Pour respecter ces contraintes à l’échelle et réussir le développement puis l’industrialisation de votre projet d’IA Conversationnel (Chatbot, assistant virtuel et tout autre système conversationnel), nous avons suivi un cadre méthodologique rigoureux que nous allons vous présenter dans ce guide.
N’hésitez pas à m’envoyer un message via Linkedin pour me partager vos retours sur ce guide. https://www.linkedin.com/in/eliothallak/Je serais également heureux de répondre à vos questions si vous souhaitez me partager vos challenges et enjeux sur un projet IA en cours ou à venir.
Étape 1 : Définir des attentes réalistes
Il faut être réaliste
Au début d’un projet IA, les responsables métiers oublient souvent la vérité suivante : les systèmes d'IA générative conversationnelle ne visent pas la perfection absolue. Même les agents humains commettent des erreurs et n'obtiennent pas systématiquement de bons scores lors des évaluations.
L’objectif est de concevoir un projet IA qui fera au moins aussi bien que les humains, qui font eux-mêmes des erreurs.
Questions structurantes
Avant de vous lancer, posez-vous ces questions :
- Quel est le taux de résolution minimum acceptable pour votre cas d'usage ?
- Quelles sont les conséquences business/métier d'une mauvaise réponse dans votre contexte ?
- Disposez-vous des ressources nécessaires pour une supervision humaine (Human In The Loop) ?
- Quels types de questions/requêtes le système doit-il gérer (informationnel, transactionnel, support technique) ?
- Quel est le niveau de risque réputationnel acceptable ?
Maintenant que nous avons posé un cadre réaliste pour le projet, en définissant ce que "succès" signifie et en se posant les questions fondamentales sur les ressources et les objectifs, nous devons cartographier les risques potentiels pour mieux les maîtriser.
Étape 2 : Identifier les types d'erreurs et leur gravité

Taxonomie des erreurs
La classification des erreurs par niveau de gravité permet de prioriser vos efforts de modération et de définir des seuils de tolérance par types d’erreurs.
L’objectif n’est pas de régler tous les problèmes. L’objectif est d’identifier les problèmes que nous devons régler et de trouver une solution qui atténuera suffisamment le risque et non pas une solution parfaite.

Voici plusieurs exemples par catégorie d’erreurs afin d’illustrer le propos.
Erreurs critiques (tolérance zéro)
- Hallucinations factuelles : Le système invente des informations (prix, politiques, procédures)
- Conseils dangereux : Recommandations susceptibles de causer un préjudice
- Violations de conformité : Non-respect des réglementations (RGPD, garanties légales, sectorielles)
- Gestion inappropriée de données sensibles : Fuite ou mauvaise manipulation d'informations personnelles
- Ton inapproprié : Réponses offensantes, discriminatoires ou contraires aux valeurs de votre organisation
Erreurs moyennes (tolérance limitée)
- Incompréhension de la requête : Réponse hors-sujet mais sans conséquence grave
- Informations incomplètes : Réponse partiellement correcte nécessitant des échanges supplémentaires
- Incohérence conversationnelle : Contradictions au sein d'une même interaction
- Absence de personnalisation : Réponses génériques ignorant le contexte client disponible
Erreurs mineures (tolérance élevée)
- Formulation sous-optimale : Réponse correcte mais expression maladroite
- Redondance : Répétitions inutiles allongeant l'interaction
- Longueur inadaptée : Verbosité excessive ou concision insuffisante
Nous avons désormais une vision claire des types d'erreurs possibles et de leur impact potentiel sur ce projet. En créant une taxonomie et une matrice de risque, nous savons quoi surveiller.
Cependant, identifier les symptômes ne suffit pas ; pour construire un système robuste, il faut en comprendre les causes profondes. Les erreurs que nous venons de lister ne sont souvent que la partie visible de l'iceberg.
Il est donc temps de plonger dans la mécanique du modèle pour analyser ses biais et limitations intrinsèques.
Étape 3 : Analyser les biais et limitations du modèle
Biais inhérents aux données d'entraînement
Il s’agit d’un problème que nous rencontrons systématiquement : les modèles de langage sont entraînés sur des corpus de données web génériques, ce qui génère plusieurs catégories de biais incompatibles avec un usage professionnel.
Sources de biais identifiées
- Écart entre langage web informel et communication professionnelle
- Sur-représentation de certains scénarios au détriment de cas métier spécifiques
- Absence de connaissance des politiques et procédures internes de votre organisation
- Biais culturels et linguistiques des données d'entraînement
Méthodologie d'évaluation
- Constituez un corpus de cas représentatifs de votre domaine métier
- Identifiez systématiquement les lacunes de connaissance spécifique
- Mesurez l'alignement avec les guidelines de communication de votre organisation
- Documentez les écarts entre réponses générées et standards attendus
Si ce sujet vous intéresse, nous avons réalisé un guide complet sur le sujet des biais au sein des algorithmes et nos meilleures stratégies pour les atténuer.Si vous souhaitez recevoir notre guide, n'hésitez pas à contacter Eliot Hallak sur LinkedIn.
Exemple - Secteur e-commerce
Requête client : "Je souhaite annuler ma commande"
Réponse biaisée (connaissance générique) :
"Les annulations ne sont généralement pas possibles après validation de la commande."
Réponse attendue (connaissance métier) :
"Je consulte immédiatement le statut de votre commande. Conformément à notre politique, l'annulation reste possible tant que la commande n'a pas été expédiée, soit dans un délai de 24h ouvrées suivant la validation."
L'écart entre ces deux réponses illustre la nécessité d'une intégration fine de la connaissance métier, impossible à obtenir uniquement via le modèle de base.
Biais de ton et registre de langue
Nous avons vu que le modèle peut se tromper sur les faits à cause de ses données d'entraînement. Mais ce que le modèle dit n'est que la moitié du problème.
Comment il le dit est tout aussi critique pour votre image de marque. Un ton trop familier pour une marque de luxe ou trop rigide pour une startup peut créer une dissonance immédiate avec vos clients.
Risques identifiés
- Inadéquation entre ton du modèle et positionnement de marque (premium vs. accessible)
- Incohérence de registre au sein d'une même conversation
- Basculement inapproprié entre formalité et familiarité
Démarche d'évaluation
- Définissez précisément vos guidelines de ton (axes : professionnalisme, empathie, accessibilité)
- Générez 100+ conversations simulées couvrant différents scénarios
- Évaluez l'alignement avec votre voix de marque via panel d'experts internes
- Quantifiez les écarts et leur impact sur la perception de marque
Limitations de gestion du contexte
Après avoir analysé le contenu et le style de chaque message individuel, il faut maintenant prendre de la hauteur.
Une conversation réussie n'est pas une simple succession de bonnes réponses, c'est un dialogue cohérent. C'est là qu'on s'attaque à l'un des plus grands défis techniques de l'IA conversationnelle : sa capacité à se souvenir.
Problématiques récurrentes
- Perte de mémoire conversationnelle : Le système oublie des informations mentionnées dans les échanges précédents
- Contexte client insuffisant : Absence d'accès aux données transactionnelles et historiques
- Résolution d'ambiguïtés : Difficulté à gérer les références implicites ("ça", "cette commande", "le produit")
Stratégies de d’atténuation possibles
- Intégration avec vos systèmes CRM et bases de données transactionnelles
- Architecture de gestion de la mémoire conversationnelle
- Mécanismes de clarification proactive en cas d'ambiguïté détectée
- Définition de règles d'escalade en cas de contexte insuffisant
À ce stade, nous avons disséqué le "pourquoi" des erreurs potentielles en explorant les biais et les limitations techniques du modèle.
Nous comprenons les faiblesses fondamentales du projet. Nous devons à présent définir la couverture fonctionnelle de notre agent conversationnel et prioriser les types de questions que nous souhaitons traiter.
Étape 4 : Évaluer les cas d'usage que vous souhaitez traiter
Classification par niveau de risque
La segmentation des cas d'usage par niveau de risque permet de définir des stratégies de déploiement adaptée et d'optimiser l'allocation de vos ressources lors de l’industrialisation du projet.

Cas d'usage à faible risque (candidats prioritaires pour automatisation complète)
- Réponses à questions fréquentes standardisées (horaires, politiques de retour)
- Suivi de commande et statut de livraison
- Informations produit factuelles et documentées
- Redirection vers ressources self-service existantes
Cas d'usage à risque modéré (automatisation avec garde-fous renforcés)
- Recommandations produit personnalisées
- Résolution de problèmes techniques courants
- Gestion de compte (modifications d'adresse, préférences)
- Questions relatives aux promotions et tarification
Cas d'usage à risque élevé (supervision humaine obligatoire ou exclusion du périmètre)
- Traitement de remboursements et litiges financiers
- Gestion de situations de fraude ou sécurité
- Réclamations à dimension juridique
- Situations émotionnellement sensibles (produit défectueux présentant un danger)
Exemple de matrice de priorisation
L'élaboration d'une matrice de priorisation spécifique par type de requêtes que vous souhaitez traiter est essentiel car vous ne pourrez pas traiter tous les types de requêtes avec votre agent IA conversationnel.
Vous pouvez par exemple vous concentrer sur les typologies de requêtes qui sont les plus fréquentes ou qui ont une complexité faible ou encore celle où la probabilité d'erreur est faible.
Exemple : Types de requêtes pour un agent IA e-commerce
La classification de ces types de requêtes au sein d’une matrice de priorisation permettra de prioriser le déploiement de l'agent IA : commencer par les requêtes à forte fréquence, faible complexité et faible risque (suivi de commande, politiques de retour, informations produit), puis étendre progressivement vers les cas d'usage plus complexes une fois les mécanismes de supervision validés.
Cette matrice doit être validée par les parties prenantes métier et juridiques avant tout développement.

Livrables de cette étape
- Cartographie exhaustive des types de requêtes (analyse de vos tickets historiques)
- Classification de chaque type par niveau de risque et volume
- Définition du périmètre initial (recommandation : démarrage sur faible risque uniquement)
- Spécification des règles d'escalade vers agent humain
- Roadmap de déploiement progressif par cas d'usage
Nous avons maintenant segmenté les interactions possibles avec le système, en identifiant les cas d'usage prioritaires et ceux qui nécessitent une prudence maximale.
Cette cartographie est essentielle pour définir une stratégie de déploiement intelligente.
Mais comment savoir si notre chatbot performe bien sur les cas d'usage à faible risque ? Comment mesurer objectivement la qualité ? Pour passer de l'évaluation subjective à une décision pilotée par la donnée, il nous faut un tableau de bord clair.
L'étape suivante consiste donc à définir les indicateurs clés qui nous permettront de quantifier le succès.
Étape 5 : Définir les métriques d'évaluation
Insuffisance des métriques techniques isolées
Les métriques purement techniques (temps de réponse, disponibilité, efficacité du modèle) sont nécessaires mais insuffisantes pour valider la qualité d'un système conversationnel en contexte professionnel.
Une évaluation robuste requiert une approche multi-dimensionnelle combinant métriques quantitatives et évaluation qualitative.

Métriques de qualité des réponses
Cette première catégorie de métriques s'attaque au cœur du réacteur : la qualité intrinsèque de la réponse générée.
Avant même de savoir si l'expérience est agréable ou si le système est sécurisé, il faut répondre à la question la plus fondamentale : la réponse fournie est-elle correcte, pertinente et complète ? Ces indicateurs mesurent servent à mesurer la performance du modèle.

Métriques d'expérience utilisateur

Métriques de sécurité et conformité
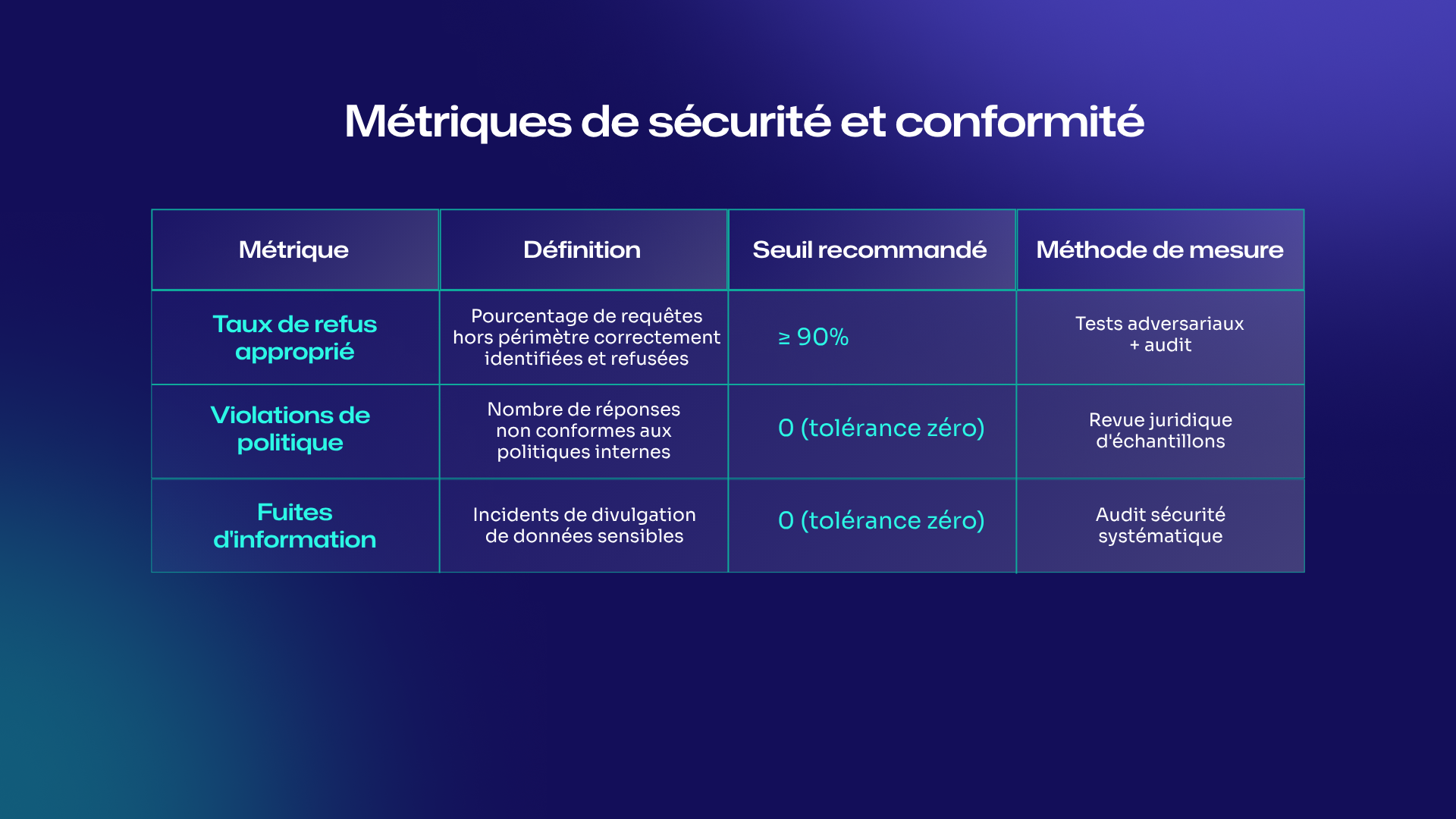
Pour évaluer ces différentes métriques, nous pouvons notamment utilisé deux types d’évaluation. L’évaluation humaine et l’évaluation via IA.
Évaluation humaine qualitative
L'évaluation humaine reste le meilleur standard pour mesurer la qualité perçue et l'adéquation aux standards professionnels.
Exemple de grille d'évaluation (échelle 1-5)
- Exactitude factuelle
- Pertinence de la réponse par rapport à la requête
- Clarté et compréhensibilité
- Ton et professionnalisme
- Utilité effective pour résoudre le problème client
Le protocole d'évaluation
- Phase pré-lancement : Minimum 500 conversations annotées par panel d'experts
- Phase post-lancement : Audit hebdomadaire de 100 conversations sélectionnées aléatoirement
- Évaluateurs : Agents support expérimentés, experts métier, représentants clients
Point d’attention : Le coût et ROI de l'évaluation humaine
L'évaluation humaine représente un investissement significatif mais indispensable. Son coût doit être intégré dès la phase de cadrage budgétaire. Son ROI devient positif dès lors qu'elle permet d'éviter un seul incident majeur de réputation ou de conformité.
L'absence d'évaluation humaine rigoureuse constitue un facteur de risque majeur pour la mise en production.
L’évaluation automatisée via un système “LLM-as-a-Judge”
L'évaluation humaine systématique, bien qu'essentielle pour garantir la qualité, présente des limitations importantes en termes de scalabilité et de coût.
Pour maintenir une surveillance continue et exhaustive de la santé de votre agent IA post-déploiement, l'approche LLM-as-a-Judge offre une solution complémentaire puissante.
Principe fondamental : Utiliser un modèle supérieur comme évaluateur
La stratégie consiste à déployer une architecture à deux niveaux :
- Modèle de production : Modèle rapide et économique (GPT-4o, Claude 3.5 Sonnet, Gemini 2.5 flash etc..) pour répondre aux utilisateurs en temps réel
- Modèle évaluateur : Modèle plus puissant avec capacités de raisonnement avancées (GPT-o3, Claude 3.7 Sonnet, o1 etc…) pour évaluer la qualité des réponses a posteriori
Cette asymétrie permet d'optimiser le compromis coût/latence pour l'expérience utilisateur tout en maintenant des standards d'évaluation élevés.
Stratégies d'échantillonnage pour l'évaluation scalable
L'évaluation exhaustive (100% des conversations) peut être coûteuse à grande échelle. Voici des stratégies d'échantillonnage intelligentes :
Avec un framework de métriques solide, nous avons maintenant les outils pour mesurer la performance de notre agent IA conversationnel de manière objective.
Nous savons ce que "bon" signifie en termes de qualité, d'expérience utilisateur et de sécurité.
Cependant, ces métriques ne vivent pas en vase clos. Un même système, avec les mêmes métriques, peut être perçu très différemment selon le contexte de l'interaction.
Étape 6 : Analyser l'impact du canal et du contexte
Nous allons examiner comment le canal de communication et les situations spécifiques (comme l'état émotionnel du client ou la complexité de sa demande) modifient le niveau de risque et doivent influencer la stratégie de déploiement.
Risques différenciés par canal de communication
Le niveau de risque et les attentes utilisateurs varient significativement selon le canal de communication.
Le canal de communication définit le cadre de l'interaction, mais le contexte est souvent bien plus riche. Au-delà du support technique (chat, email, etc.), il faut considérer la situation spécifique du client : où se trouve-t-il dans son parcours, quel est son état émotionnel, et quelle est la complexité de sa demande ?
Ces facteurs humains et situationnels sont souvent les plus déterminants pour le succès ou l'échec d'une interaction via IA.
Position dans le parcours client
Le niveau de risque augmente proportionnellement à l'avancement dans le parcours client et à la criticité de la situation.
Pré-achat (découverte, information) → Risque faible
↓
Achat (transaction, validation) → Risque modéré
↓
Post-achat (suivi, problème mineur) → Risque modéré à élevé
↓
Litige (réclamation, insatisfaction majeure) → Risque critique
État émotionnel du client
La détection et la gestion appropriée de l'état émotionnel constituent un facteur critique de succès.
- Client neutre ou curieux : Automatisation adaptée
- Client frustré : Automatisation avec empathie renforcée et seuil d'escalade abaissé
- Client en colère : Escalade immédiate vers agent humain recommandée
Nous avons maintenant une compréhension à 360 degrés des risques : ce qui peut mal tourner, pourquoi, dans quels scénarios, comment le mesurer, et comment le contexte influence le tout.
Toute cette analyse théorique est fondamentale, mais elle ne vaut rien sans une mise en pratique rigoureuse. Il est temps de passer de la stratégie à l'exécution.
L'étape suivante consiste à traduire cette connaissance en un plan d'action concret pour tester, valider et sécuriser le système avant qu'il n'interagisse avec le moindre client.
Étape 7 : Structurer le plan de test et validation
Cette étape est le cœur opérationnel de notre démarche de réduction des risques.
Nous allons y détailler le plan d'action concret pour tester, valider et sécuriser le système avant qu'il n'interagisse avec le moindre client, en couvrant les phases de pré-lancement, de déploiement progressif et de monitoring continu.
Phase 1 : Tests pré-lancement
A. Analyse de l'existant et constitution du corpus de test
Extraction et analyse de données historiques
- Extrayez un échantillon représentatif de 1000+ conversations client réelles (anonymisées conformément au RGPD)
- Identifiez les patterns de requêtes et leur distribution
- Catégorisez par type, complexité et issue de résolution
B. Batterie de tests automatisés

Exemple de spécification de test fonctionnel

C. Évaluation humaine comparative
Constitution du panel d'évaluateurs
- Agents support expérimentés (connaissance des bonnes pratiques)
- Représentants de profils clients diversifiés
- Experts métier (juridique, produit, qualité)
Protocole d'évaluation standardisé
- Présentation de conversations en double aveugle (GenAI Vs. agent humain)
- Évaluation selon grille standardisée
- Identification de la préférence avec justification argumentée
- Notation des erreurs critiques
Seuils de validation pour passage en phase suivante
- GenAI préféré ou jugé équivalent : ≥ 70% des cas évalués
- Absence totale d'erreur critique : 100% requis (tolérance zéro)
- Score moyen de qualité : ≥ 4/5 sur l'ensemble des dimensions
Une fois les tests pré-lancement validés, le système a prouvé sa robustesse dans un environnement contrôlé.
L'étape suivante consiste à le confronter progressivement au monde réel.
Cette phase de déploiement progressif est critique : elle permet de collecter des données réelles tout en maîtrisant l'exposition au risque, grâce à une montée en charge par paliers et des mécanismes de sécurité renforcés.
Phase 2 : Déploiement progressif
Approche recommandée : Déploiement par étapes avec validation à chaque palier
.png)
Étape 1 : Pilote interne (durée : 2-4 semaines)
- Déploiement limité à votre équipe support interne
- Utilisation en conditions réelles mais avec filet de sécurité
- Collecte intensive de feedback qualitatif
- Capacité d'ajustement rapide sans impact client
Étape 2 : Beta fermée (durée : 4-6 semaines)
- Exposition à 5-10% du trafic client réel
- Segmentation sur profil à faible risque (clients fidèles, requêtes simples)
- Monitoring continu 24/7
- Mécanisme de rollback immédiat en cas de problème
Étape 3 : Déploiement graduel (durée : 8-12 semaines)
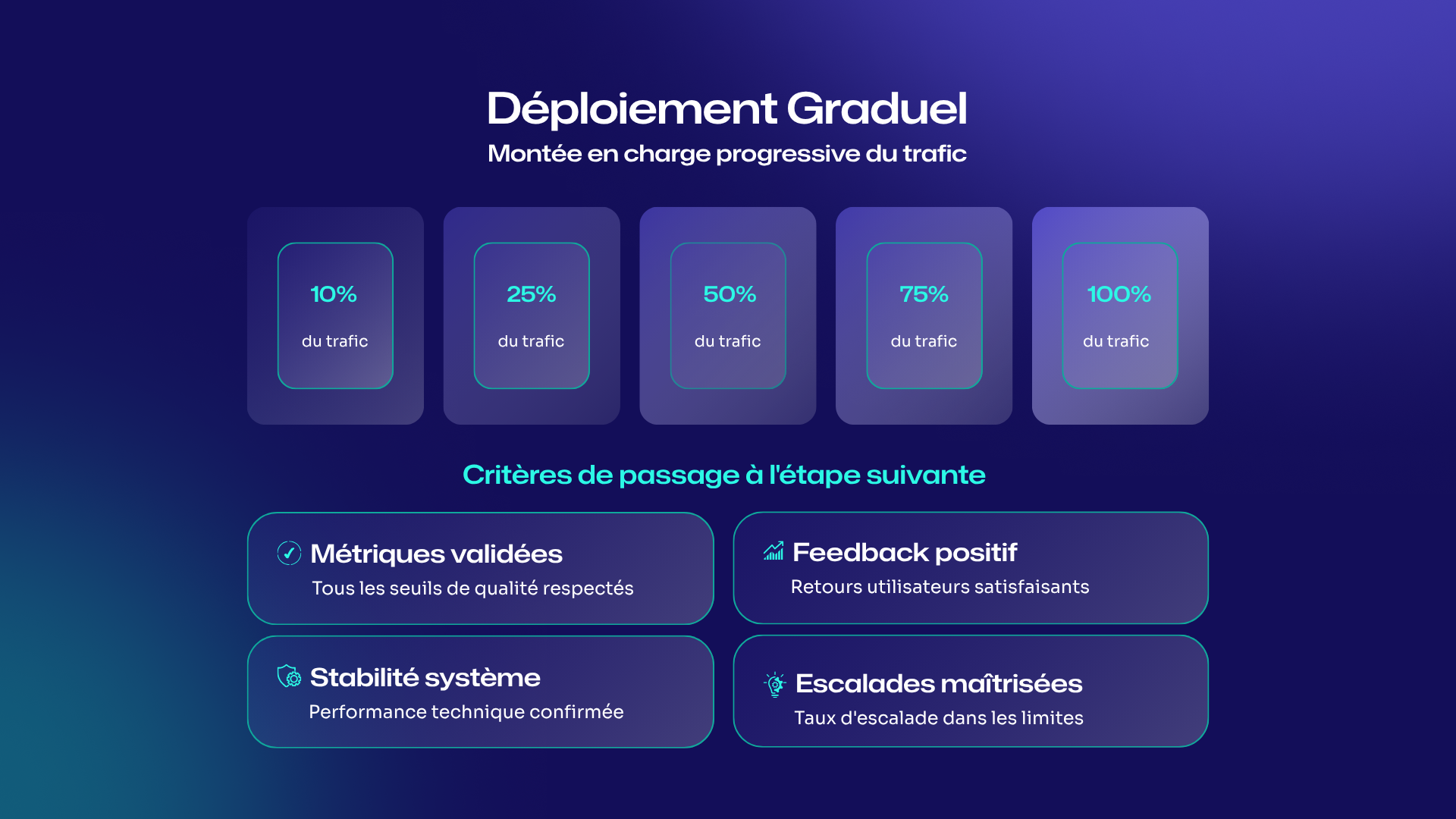
Garde-fous techniques à chaque étape
Règles d'escalade automatique
Escalade immédiate déclenchée si :
- Détection de mots-clés critiques ("avocat", "danger", "blessure", "DGCCRF")
- Score de sentiment très négatif (< -0.7 sur échelle normalisée)
- Requête identifiée comme hors périmètre défini
- Conversation dépassant 10 tours sans résolution
- Demande explicite du client de parler à un humain
- Détection d'indicateurs de fraude ou problème de sécuritéFiltres de sécurité et validation
- Validation systématique des informations factuelles au sein de la base de connaissances (prix, dates, politiques)
- Blocage automatique de réponses contenant des données sensibles (numéros de carte, mots de passe)
- Vérification de cohérence avec documentation officielle
- Détection d'anomalies statistiques dans les réponses générées
Stratégies Human-in-the-Loop (HITL)
Le Human-in-the-Loop (HITL) : L'humain ne remplace pas l'IA, mais agit comme filet de sécurité, superviseur ou validateur selon le niveau de risque. Le système GenAI génère des propositions, l'humain garantit leur qualité et leur pertinence.
Le système Human in the loop permet :
- Communiquer rapidement le rôle de l'expertise humaine aux côtés de l'IA
- Rassurer les parties prenantes sur la robustesse du système
- Servir de référence rapide lors de discussions transversales
- Compléter les documents de spécification produit
Le placement de la revue humaine au sein du processus dépend largement des processus déjà en place dans l'organisation. Pour la plupart des équipes de support client en entreprise, il existe normalement déjà une couche de revue humaine dans le processus d'assurance qualité.
Par conséquent, pour un pilote ou un déploiement à petite échelle, l'une des façons les moins perturbatrices d'ajouter la revue humaine nécessaire au support GenAI consiste à réutiliser ou modifier la grille d'évaluation QA que les agents QA utilisent déjà pour évaluer la performance des agents de support.
Enfin, afin de décider de où est-ce que nous allons intégrer de la supervision humaine au sein du périmètre fonctionnel de notre produit IA, nous devons également réaliser une matrice qui nous permettra de déterminer quels sont les questions les plus critiques de notre périmètre fonctionnel qui nécessite une supervision.

.png)
Les 3 bénéfices du système HITL
1. Réduction des risques opérationnels
- Prévention des erreurs critiques avant qu'elles n'atteignent le client
- Détection précoce de dérives du modèle (hallucinations, réponses inappropriées)
- Protection de la réputation de marque
2. Amélioration continue accélérée
- Collecte de données de qualité pour le fine-tuning du modèle
- Identification rapide des lacunes de la base de connaissances
3. Montée en compétence progressive
- Déploiement plus rapide avec supervision initiale forte
- Réduction graduelle de l'intervention humaine à mesure que le système mature
- Construction de confiance auprès des équipes et du management
- Transition douce vers l'autonomie complète du système
La stratégie HITL avec supervision permet de déployer une solution GenAI conversationnelle de manière progressive et sécurisée.
Elle transforme le risque initial en opportunité d'apprentissage accéléré, tout en garantissant la qualité de service.
L'investissement en ressources humaines pour la supervision est temporaire et décroissant, avec un ROI clairement mesurable en termes de réduction des risques et d'amélioration continue.
Les points d'attention lors de cette phase :
- Charge cognitive : Les équipes doivent jongler entre leurs tâches habituelles et l'apprentissage de nouveaux processus
- Infrastructure de données : Les pipelines de données et tableaux de bord ne sont généralement pas encore en place, nécessitant du reporting manuel
- Définition de la qualité : La notion d'interaction de support client "de haute qualité" peut être subjective ; des définitions claires et partagées sont cruciales pour le succès
Le déploiement progressif a permis de valider la performance du système en conditions réelles et de l'exposer à un trafic croissant.
Une fois le système entièrement déployé, notre travail ne s'arrête pas. Au contraire, nous entrons dans une nouvelle phase, celle du monitoring et de l'amélioration continue.
Phase 3 : Monitoring post-lancement et amélioration continue
Ce sujet est tellement critique et décisif que nous avons décidé d’en faire un guide complet qui paraîtra dans quelques semaines. Selon nous, la majorité des échecs lors de la phase d’industrialisation interviennent à ce stade. Les entreprises sont encore assez peu matures sur le monitoring d’un projet LLM (Data drift, régression de prompt, optimisation du reranking, automated red teaming, evolution du semantic caching …) les particularités et les risques lors du déploiement d’un projet GenAI sont nombreux.Si vous souhaitez recevoir notre guide, n'hésitez pas à contacter Eliot Hallak sur LinkedIn, qui vous l'enverra dès sa sortie.
Dashboard de monitoring temps réel
Pour simplifier, il existe trois types de métriques à évaluer :
- La qualité
- La sécurité
- Les coûts
Pour chacun de ces enjeux, il existe de nombreuses problématiques d’industrialisation et des stratégies de monitoring à mettre en place pour pouvoir surmonter les challenges très spécifiques de l’industrialisation d’un projet GenAI.
Nous reviendrons dessus dans notre guide dédié.
Le programme d'audits réguliers
Le monitoring en temps réel et le système Human In The Loop est votre système d'alerte précoce, indispensable pour la réactivité au quotidien.
Cependant, se fier uniquement aux métriques automatisées peut masquer des problèmes de qualité plus subtils.
C'est là qu'intervient le programme d'audits réguliers. Il s'agit d'une démarche proactive et qualitative pour garantir que la performance mesurée correspond bien à la qualité perçue par vos clients.
.png)
Processus d'amélioration continue structuréLe monitoring en temps réel et les audits réguliers vous fournissent un flux constant de données et d'informations qualitatives. Cependant, la collecte d'informations n'est que la moitié du travail. La véritable valeur se crée lorsque ces enseignements sont transformés en améliorations concrètes du système. Cette section détaille le processus structuré qui permet de fermer la boucle : un cycle itératif inspiré du Lean Management pour analyser les échecs, prioriser les actions, et valider l'impact des changements, garantissant que votre système GenAI ne stagne jamais et s'améliore continuellement.
1. Collecte de feedback multi-sources
- Feedback explicite utilisateur (satisfaction, commentaires)
- Feedback implicite (escalades, abandons, durée d'interaction)
- Feedback équipe support (remontées terrain)
- Verbatims clients analysés qualitativement
2. Analyse systématique des échecs
- Catégorisation des erreurs selon taxonomie établie
- Identification de patterns récurrents
- Priorisation par matrice impact × fréquence
- Analyse des causes racines
3. Itérations et optimisations
- Enrichissement de la base de connaissances
- Affinement des prompts système
- Ajustement des règles d'escalade
- Fine-tuning du modèle si justifié par le ROI
4. A/B testing rigoureux
- Tests de variations de prompts sur segments de trafic
- Comparaison d'approches alternatives
- Mesure d'impact statistiquement significatif sur métriques clés
- Déploiement de la variante gagnante
Le plan de test et de déploiement progressif nous a fourni un cadre opérationnel pour lancer le système de manière sécurisée.
À l'issue de ces phases, nous disposerons d'une quantité significative de données sur la performance de notre agent IA.
La question finale, et la plus critique pour le business, est alors : "Est-ce que l'on appuie sur le bouton ?". Pour répondre à cette question, il ne suffit pas d'avoir des données ; il faut un outil de décision clair qui synthétise l'ensemble des résultats et permet de prendre une décision de lancement éclairée et assumée.
Étape 8 : La matrice de décision Go/No-Go
Cette dernière étape est celle de la décision. Après avoir analysé, testé en production et mesuré, nous disposons de toutes les données nécessaires pour prendre une décision de lancement éclairée.
Cette section présente les outils qui permettent de synthétiser ces informations et de valider formellement le passage en production à 100%.
Le tableau de bord de décision
La décision de mise en production repose sur une évaluation multi-dimensionnelle avec des seuils de validation clairement définis.
Le calcul du score composite
Le tableau de bord de décision fournit une vue détaillée, mais pour une prise de décision finale, il est essentiel de synthétiser ces multiples indicateurs en un seul score objectif.
Le score composite répond à ce besoin. Il agrège la performance de chaque dimension en appliquant la pondération définie, offrant ainsi une mesure globale et équilibrée de la maturité du projet. Ce score unique permet ensuite d'appliquer la grille de décision de manière claire et non ambiguë.
.png)
La grille de décision
- Score ≥ 90% ET aucune erreur critique : Validation pour lancement
- Score 75-89% ET plan HITL robuste validé : Lancement conditionnel avec supervision renforcée
- Score < 75% OU présence d'erreurs critiques : Refus de lancement, itérations nécessaires
Le tableau de bord de décision nous donne le "Go" stratégique basé sur les données.
Cependant, avant le lancement effectif, une dernière vérification opérationnelle est indispensable.
La checklist de validation finale ou “Runbook” agit comme un ultime filet de sécurité, garantissant que tous les aspects techniques, organisationnels et de conformité sont bien en place.
La checklist de validation finale
Préparation technique
- [ ] Ensemble des tests automatisés validés à 100%
- [ ] Évaluation humaine complétée sur minimum 500 conversations
- [ ] Score composite au-dessus du seuil défini
- [ ] Garde-fous IA implémentés et testés en conditions réelles
- [ ] Règles d'escalade configurées et validées
- [ ] Infrastructure de monitoring opérationnelle
- [ ] Plan de rollback testé et documenté
Préparation organisationnelle
- [ ] Formation de l'équipe support complétée et validée
- [ ] Processus HITL défini, documenté et testé
- [ ] Responsabilités et astreintes formellement assignées
- [ ] Communication interne effectuée auprès de toutes les parties prenantes
- [ ] Plan de communication client préparé et validé
Conformité et gestion des risques
- [ ] Revue juridique complétée (RGPD, mentions légales, conformité sectorielle)
- [ ] Analyse de risques validée par la direction
- [ ] Plan de gestion de crise défini et testé
- [ ] Couverture assurantielle vérifiée et adaptée
- [ ] Audit sécurité réalisé par équipe indépendante
Documentation
- [ ] Documentation technique exhaustive et à jour
- [ ] Runbook opérationnel créé et validé
- [ ] FAQ interne pour équipe support disponible
- [ ] Métriques et KPIs documentés avec définitions précises
Nous avons parcouru l'ensemble du processus, de la définition des attentes à la décision finale de lancement. Chaque étape a permis de construire une couche de sécurité et de compréhension supplémentaire.
Pour finir, voici quelques erreurs couramment commises et qui peuvent s’avérer très couteuses.
Les erreurs critiques à éviter
Se fier uniquement aux métriques automatiques
Les métriques techniques (BLEU, perplexité) ne corrèlent que faiblement avec la satisfaction utilisateur et la qualité perçue en contexte professionnel.
Négliger le monitoring post-lancement
La qualité peut se dégrader dans le temps (drift du modèle, évolution des requêtes). Une surveillance continue est indispensable. Guide à venir sur ce sujet
Vouloir tout automatiser immédiatement
L'automatisation doit être progressive. Les cas complexes nécessitent une supervision humaine, potentiellement de manière permanente.
Ignorer le feedback terrain
Vos agents support et vos clients détectent les problèmes avant que les métriques ne les révèlent. Leurs remontées doivent être systématiquement analysées.
Note : Ce guide constitue un document évolutif. Il doit être adapté au contexte spécifique de chaque organisation. Nous le mettrons également à jour régulièrement suite à nos dernières expériences et apprentissages lors des missions réalisées pour nos clients.
Vous souhaitez nous partager vos challenges et enjeux sur un projet IA ? Contactez-nous en envoyant un message via linkedin : https://www.linkedin.com/in/eliothallak/
Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript
